
前言
表格存储是阿里云自研分布式存储系统,可以用来存储海量结构化、半结构化的数据。表格存储支持高性能和容量型两种实例类型。高性能使用SSD的存储介质,针对读多写多的场景都有较好的访问延时。容量型使用的是SSD和SATA混合的存储介质。对写多的场景,性能接近高性能,读方面,如果遇到冷数据产生读SATA盘的话,延时会比高性能上涨一个量级。在海量数据存储场景下,例如时序场景,我们会希望最新的数据可以支持高性能查询,较早的数据的读写频次都会低很多。这时候一个基于表格存储高性能和容量型存储分层的需求就产生了。
方案细节
表格存储近期对外正式发布的全增量一体的通道服务,通道服务基于表格存储数据接口之上的全增量一体化服务。通道服务为用户提供了增量、全量、增量加全量三种类型的分布式数据实时消费通道。有了通道服务,我们可以很方便的构建从高性能实例下的表到容量型表之间的实时数据同步,进而可以在高性能表上使用表格存储的特性数据生命周期,根据业务需求设置一个合理的TTL。
总体来说就可以构建一个如下图所示的架构: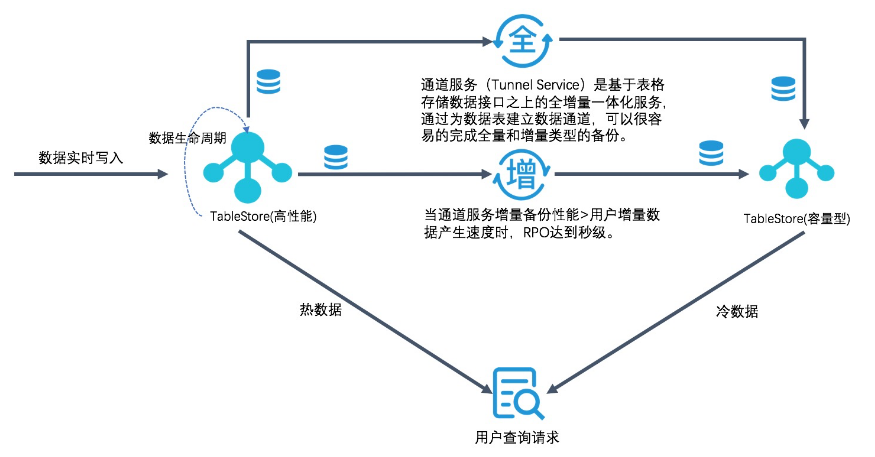 整个数据的流动过程如下:
整个数据的流动过程如下: - 业务写入端直接写入高性能实例
- 高性能实例中的数据通过通道服务同步至容量型
- 高性能实例中的老数据自动过期,减少存储量占用
-
用户查询请求根据时序查询条件,判断是否是近期数据
- 近期数据查询进入高性能,毫秒级别返回
- 较早数据查询进入容量型,几十毫秒后返回
代码和操作流程:
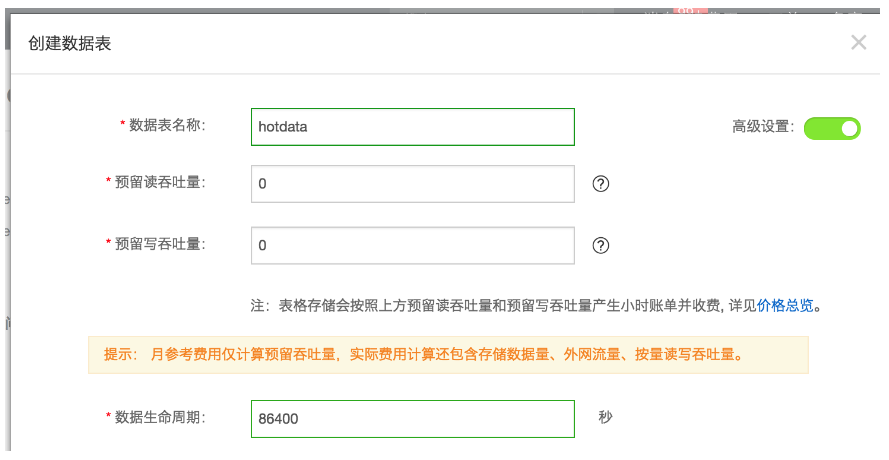
在高性能实例上根据业务主键需求创建数据表,并设置合理的数据TTL,然后在容量型下创建相同的schema的表用来持久化存储所有数据。
然后在通道页面创建一个全增量类型的通道:

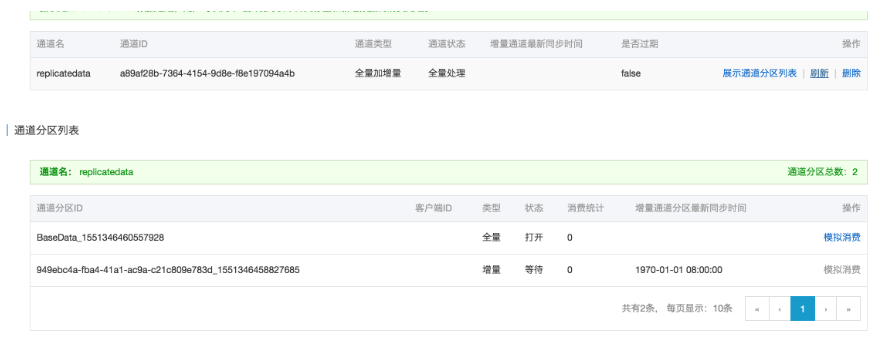
通过控制台可以简单清晰的查看到同步的状态,并发,进度等信息:
 下面贴一下通过Tunnel进行复制同样schema表TableStore表的Sample代码:
下面贴一下通过Tunnel进行复制同样schema表TableStore表的Sample代码: func main () { //高性能实例的信息 tunnelClient := tunnel.NewTunnelClient("", "", "", "") //容量型实例的信息 client := tablestore.NewClient("", "", "", "") //配置callback到SimpleProcessFactory,配置消费端TunnelWorkerConfig workConfig := &tunnel.TunnelWorkerConfig{ ProcessorFactory: &tunnel.SimpleProcessFactory{ ProcessFunc: replicateDataFunc, CustomValue: client, }, } //使用TunnelDaemon持续消费指定tunnel daemon := tunnel.NewTunnelDaemon(tunnelClient, "", workConfig) err := daemon.Run() if err != nil { fmt.Println("failed to start tunnel daemon with error:", err) }}func replicateDataFunc(ctx *tunnel.ChannelContext, records []*tunnel.Record) error { client := ctx.CustomValue.(*tablestore.TableStoreClient) fmt.Println(client) for _, rec := range records { fmt.Println("tunnel record detail:", rec.String()) updateRowRequest := new(tablestore.UpdateRowRequest) updateRowRequest.UpdateRowChange = new(tablestore.UpdateRowChange) updateRowRequest.UpdateRowChange.TableName = "coldtable" updateRowRequest.UpdateRowChange.PrimaryKey = new(tablestore.PrimaryKey) updateRowRequest.UpdateRowChange.SetCondition(tablestore.RowExistenceExpectation_IGNORE) for _, pk := range rec.PrimaryKey.PrimaryKeys { updateRowRequest.UpdateRowChange.PrimaryKey.AddPrimaryKeyColumn(pk.ColumnName, pk.Value) } for _, col := range rec.Columns { if col.Type == tunnel.RCT_Put { updateRowRequest.UpdateRowChange.PutColumn(*col.Name, col.Value) } else if col.Type == tunnel.RCT_DeleteOneVersion { updateRowRequest.UpdateRowChange.DeleteColumnWithTimestamp(*col.Name, *col.Timestamp) } else { updateRowRequest.UpdateRowChange.DeleteColumn(*col.Name) } } _, err := client.UpdateRow(updateRowRequest) if err != nil { fmt.Println("hit error when put record to cold data", err) } } fmt.Println("a round of records consumption finished") return nil} 总结
通过通道服务,存储在表格存储中的结构化,半结构化数据可以实时流出,进行加工,萃取,计算或进行同步。如果是想进一步降低冷数据的存储成本,可以参考把表格存储的数据备份到OSS归档存储。
本文为云栖社区原创内容,未经允许不得转载。